Moz Q&A is closed.
After more than 13 years, and tens of thousands of questions, Moz Q&A closed on 12th December 2024. Whilst we’re not completely removing the content - many posts will still be possible to view - we have locked both new posts and new replies. More details here.
What's the best way to test Angular JS heavy page for SEO?
-
Hi Moz community,
Our tech team has recently decided to try switching our product pages to be JavaScript dependent, this includes links, product descriptions and things like breadcrumbs in JS. Given my concerns, they will create a proof of concept with a few product pages in a QA environment so I can test the SEO implications of these changes. They are planning to use Angular 5 client side rendering without any prerendering. I suggested universal but they said the lift was too great, so we're testing to see if this works.
I've read a lot of the articles in this guide to all things SEO and JS and am fairly confident in understanding when a site uses JS and how to troubleshoot to make sure everything is getting crawled and indexed.
https://sitebulb.com/resources/guides/javascript-seo-resources/
However, I am not sure I'll be able to test the QA pages since they aren't indexable and lives behind a login. I will be able to crawl the page using Screaming Frog but that's generally regarded as what a crawler should be able to crawl and not really what Googlebot will actually be able to crawl and index.
Any thoughts on this, is this concern valid?
Thanks!
-
Hi Zack,
I think your concern here is valid (your render with Screaming Frog or any other client is unlikely to be precisely representative of what Googlebot will see/index). That said, I'm not sure there's much you can do to eliminate this knowledge gap for your QA process.
For instance, while we have seen Googlebot timing out JS rendering around the ~5s mark using the "Fetch & Render as Googlebot" functionality in Search Console (see slide 25 of Max Prin's slide deck here), there's no confirmation this time limit represents Googlebot's behavior in the wild.
Additionally, we know that Googlebot crawls with limited JS support - for instance, when a script uses JS to generate a random number, my colleague Tom Anthony found that Googlebot's random() JS function is deterministic (returns a predictable set) - so it's clear they have modified the headless version of Chrome they use to conserve computational expenses in this way. We can only assume they've taken other steps to save computing costs. This isn't baked-into Screaming Frog or any other crawling tool.
We have seen that with a 5s timeout set in Screaming Frog, the rendered result is pretty close to what "Fetch & Render as Googlebot" functionality demonstrates. And with the ubiquity of JS-driven content on the web today, provided links and content are rendered into the DOM fairly quickly (well ahead of that 5s mark), we've seen Google rendering and indexing JS content fairly reliable.
The ideal would be for your dev team to code these pages to degrade gracefully - so that even with JS support totally disabled, navigation and content elements are still rendered (they should be delivered in the page source, then enhanced with JS, if possible).
Failing that, the best you're likely to achieve here is reasonable confident that Googlebot can crawl, render and index these pages - there'll be some risk when you publish them to production.
Hope this helps somewhat - best of luck!
Thanks,
Mike
Got a burning SEO question?
Subscribe to Moz Pro to gain full access to Q&A, answer questions, and ask your own.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

What is SEO best practice to implement a site logo as an SVG?
What is SEO best practice to implement a site logo as an SVG?
Technical SEO | | twisme
Since it is possible to implement a description for SVGs it seems that it would be possible to use that for the site name. <desc>sitename</desc>
{{ STUFF }} There is also a title tag for SVGs. I’ve read in a thread from 2015 that sometimes it gets confused with the title tag in the header (at least by Moz crawler) which might cause trouble. What is state of the art here? Any experiences and/or case studies with using either method? <title>sitename</title>
{{ STUFF }} However, to me it seems either way that best practice in terms of search engines being able to crawl is to load the SVG and implement a proper alt tag: What is your opinion about this? Thanks in advance.1 -

Non-Existent Parent Pages SEO Impact
Hello, I'm working with a client that is creating a new site. They currently are using the following URL structure: http://clientname.com/products/furry-cat-muffins/ But the landing page for the directory /products/ does not actually have any content. They have a similar issue for the /about/ directory where the menu actually sends you to /about/our-story/ instead of /about/. Does it hurt SEO to have the URL structure set up in this way and also does it make sense to create 301 redirects from /about/ to /about/our-story/?
Technical SEO | | Alder0 -

Getting high priority issue for our xxx.com and xxx.com/home as duplicate pages and duplicate page titles can't seem to find anything that needs to be corrected, what might I be missing?
I am getting high priority issue for our xxx.com and xxx.com/home as reporting both duplicate pages and duplicate page titles on crawl results, I can't seem to find anything that needs to be corrected, what am I be missing? Has anyone else had a similar issue, how was it corrected?
Technical SEO | | tgwebmaster0 -

Does Title Tag location in a page's source code matter?
Currently our meta description is on line 8 for our page - http://www.paintball-online.com/Paintball-Guns-And-Markers-0Y.aspx
Technical SEO | | Istoresinc The title tag, however sits below a bunch of code on line 237
The title tag, however sits below a bunch of code on line 237
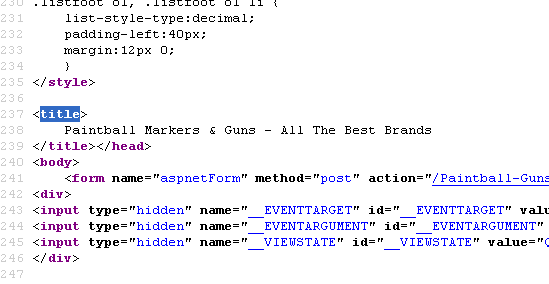 Does the location of the title tag, meta tags, and any structured data have any influence with respect to SEO and search engines? Put another way, could we benefit from moving the title tag up to the top?
I "surfed 'n surfed" and could not find any articles about this.
I would really appreciate any help on this as our site got decimated organically last May and we are looking for any help with SEO.
NIck
0
Does the location of the title tag, meta tags, and any structured data have any influence with respect to SEO and search engines? Put another way, could we benefit from moving the title tag up to the top?
I "surfed 'n surfed" and could not find any articles about this.
I would really appreciate any help on this as our site got decimated organically last May and we are looking for any help with SEO.
NIck
0 -

Does the use of sliders for text-on-page, effects SEO in any way?
The concept of using text sliders in an e-commerce site as a solution to placing SEO text above or in between product and high on ages, seems too good to be true.... or is it? How would a text slider for FAQ or other on-page text done with sliding paragraphs (similar but not this specific code- http://demo.tutorialzine.com/2010/08/dynamic-faq-jquery-yql-google-docs/faq.html) might effect text-on-page SEO. Does Google consider it hidden text? Would there be any other concerns or best practices with this design concept? faq.html
Technical SEO | | RKanfi0 -

What's the SEO impact of url suffixes?
Is there an advantage/disadvantage to adding an .html suffix to urls in a CMS like WordPress. Plugins exist to do it, but it seems better for the user to leave it off. What do search engines prefer?
Technical SEO | | Cornucopia0 -
Blocking URL's with specific parameters from Googlebot
Hi, I've discovered that Googlebot's are voting on products listed on our website and as a result are creating negative ratings by placing votes from 1 to 5 for every product. The voting function is handled using Javascript, as shown below, and the script prevents multiple votes so most products end up with a vote of 1, which translates to "poor". How do I go about using robots.txt to block a URL with specific parameters only? I'm worried that I might end up blocking the whole product listing, which would result in de-listing from Google and the loss of many highly ranked pages. DON'T want to block: http://www.mysite.com/product.php?productid=1234 WANT to block: http://www.mysite.com/product.php?mode=vote&productid=1234&vote=2 Javacript button code: onclick="javascript: document.voteform.submit();" Thanks in advance for any advice given. Regards,
Technical SEO | | aethereal
Asim0 -

Should we use Google's crawl delay setting?
We’ve been noticing a huge uptick in Google’s spidering lately, and along with it a notable worsening of render times. Yesterday, for example, Google spidered our site at a rate of 30:1 (google spider vs. organic traffic.) So in other words, for every organic page request, Google hits the site 30 times. Our render times have lengthened to an avg. of 2 seconds (and up to 2.5 seconds). Before this renewed interest Google has taken in us we were seeing closer to one second average render times, and often half of that. A year ago, the ratio of Spider to Organic was between 6:1 and 10:1. Is requesting a crawl-delay from Googlebot a viable option? Our goal would be only to reduce Googlebot traffic, and hopefully improve render times and organic traffic. Thanks, Trisha
Technical SEO | | lzhao0